Caching Strategies
Yuri Kushch / 2022-05-26
In this post we are going to take a look at different techniques for using caching approaches. This is not a deep-dive post, but rather a short intro note-reminder.
Caching
Caching is mainly about storing data in the cache. The cache is a temporary storage area relatively small in size with fast access time. Whenever your application has to read data it should first try to retrieve the data from the cache. Only if it's not found in the cache then it should try to get the data from the data store. Caching improves latency by reducing the load on your servers and databases.
Intro
If you're familiar with caching as a concept, then feel free to skip this intro.
The caching is super useful technique that makes your app work faster which means that your users suppose to wait less. Of course, caching (and as many things in software engineering) is not a silver bullet or answer to all the problems related to latency. Moreover, caching introduces other challenges like: 1) when to refresh cache? 2) what to do with stale data? 3) is it the right time to update it? 4) what if some data won't fit in cache?
Let's quickly summarize the advantages and disadvantages of caching.
Advantages:
- Perfomance. The data is co-located with the app which gives a huge performance boost.
- Network latency. We don't need to call additional service to get data (e.g. database), which saves us from additiona network hop.
- Reuse. Since data is stored in cache, the system can quickly pull data from cache and serve it without the need of going to other service/database.
Disadvantages:
- Stale data. This is one of the most common problems: when to remove/rebuild cache and how to do that properly.
- Complexity. Here, we mean the code's complexity. Since we are interacting with cache (additional component in system), then it means that the code becomes more complex. Basically, we need to maintain and understand more code. And again: how to fix the stale data if we get it. We could give our cache TTL or Time-To-Live (say, entry will live for X minutes in the cache) vs. access (it will live for N requests) vs. timed (it will live until predefined time) and variations. The more variation, the more complexity.
Strategies
Cache-Aside
This is the most simplistic one and most commonly used. Usually, cache sits aside and an application makes request to cache and data store directly. Another alternative name is lazy-loading. The flow is simple like: application first checks in the cache and then (if no entry is in the cache was found) call the database. It is mostly used with an application with read-heavy workloads.
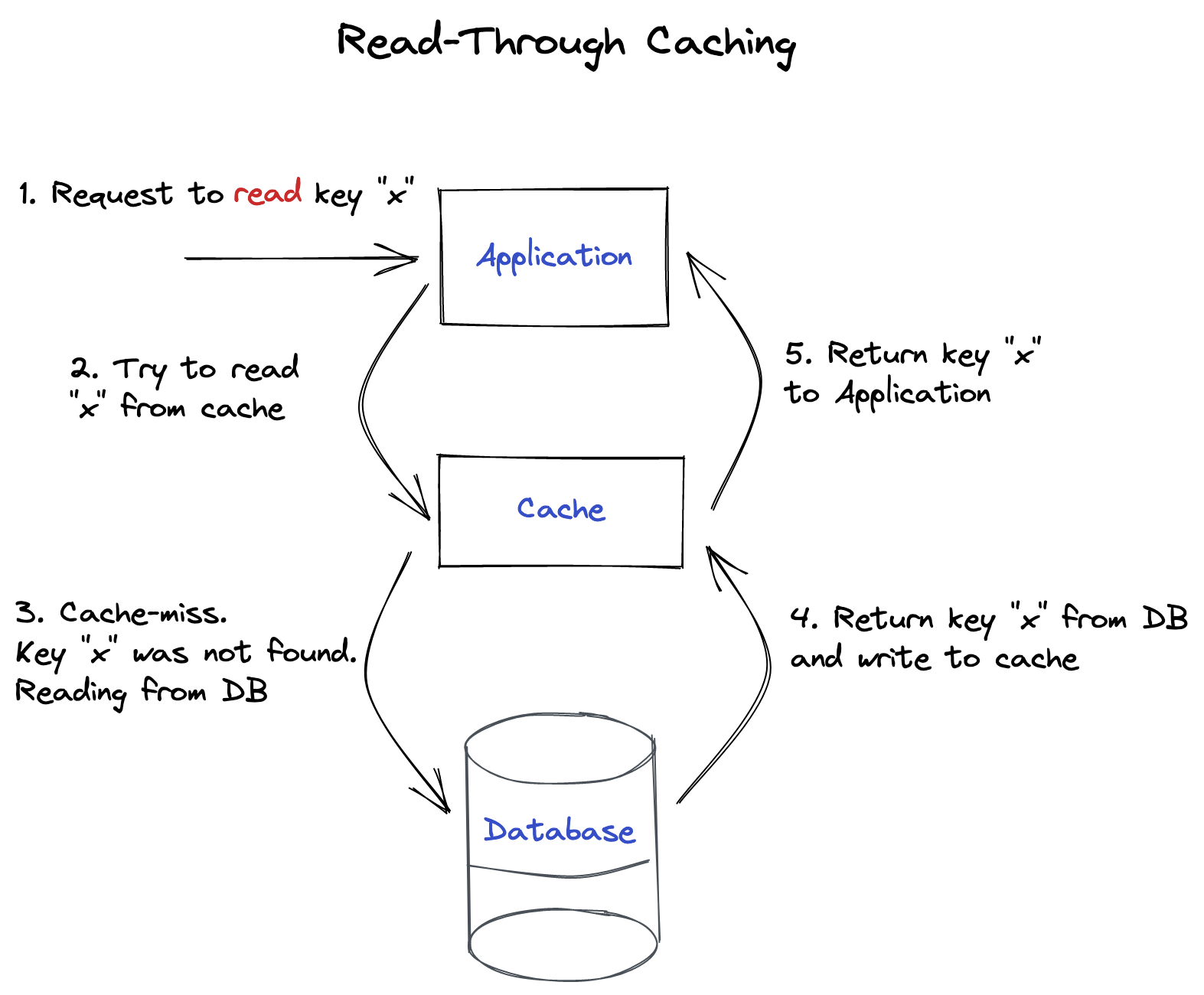
Read-Through Caching
Read-Through mean here that we are always trying to read from cache (through). If the value was not found, then our logic should go to the database and fetch the value. After the value was recevied, we should put/update cache and return it. This approach has a performance hit in case of cache-miss (when data was not found in cache). As we see from the diagram below, we have to go to database, then update cache and only after that return data. A better alternative in this case could be Refresh-Ahead Caching (described below).
Write-Through Caching
This approach assumes that we are going to write/update data in cache first and then do the appropriate update in database. It means that we are going to wait until the data updates properly in both: cache and database. If we need to improve the performance, there is an alternative approach: Write-Behind Caching (described below).

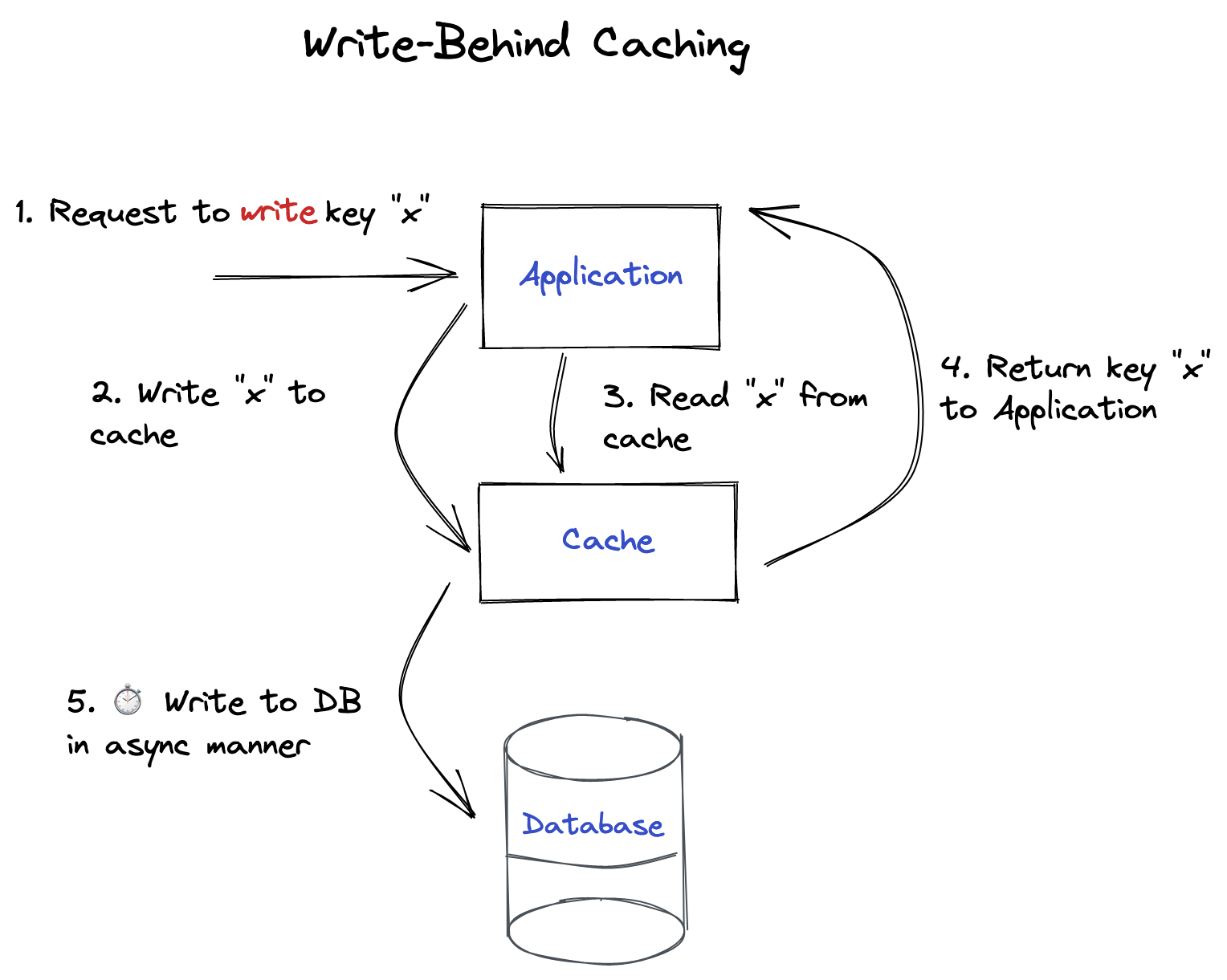
Write-Behind Caching
The "motto" of this approach is: "read once, write after some time". The main benefit of using write-behind approach is its asynchronous nature. Basically, the idea behind is the following: modified cache entries are written to the database in async manner after some dealy (e.g. N seconds/minutes/days). We should keep in mind that it is applicable only for cache inserts and updates. Deletion is happening in the synchronous manner to avoid potential issues. This approach is more complex (requires more code to write). However, it could pay off by:
- Improving application's performance as the user does not need to wait until the write will be completed;
- Additional barrier in case of failues/overloaded database server. Cache will be able to try to put data in the background later on.
- Reduced load on database server as write operation is expensive especially when thera are a lot of clients are trying to write. In this case, we are combining multiple writes into one.
Refresh-Ahead Caching
We can compare this approach to preparing dataset in the background and uploading it into cache. Obviously, not everything may fit into cache. This type of cache is useful for high number of read requests. The downside is that it requires some efforts to implement it properly, especially if we are going to implement TTL on the particular entry (instead of whole cache).

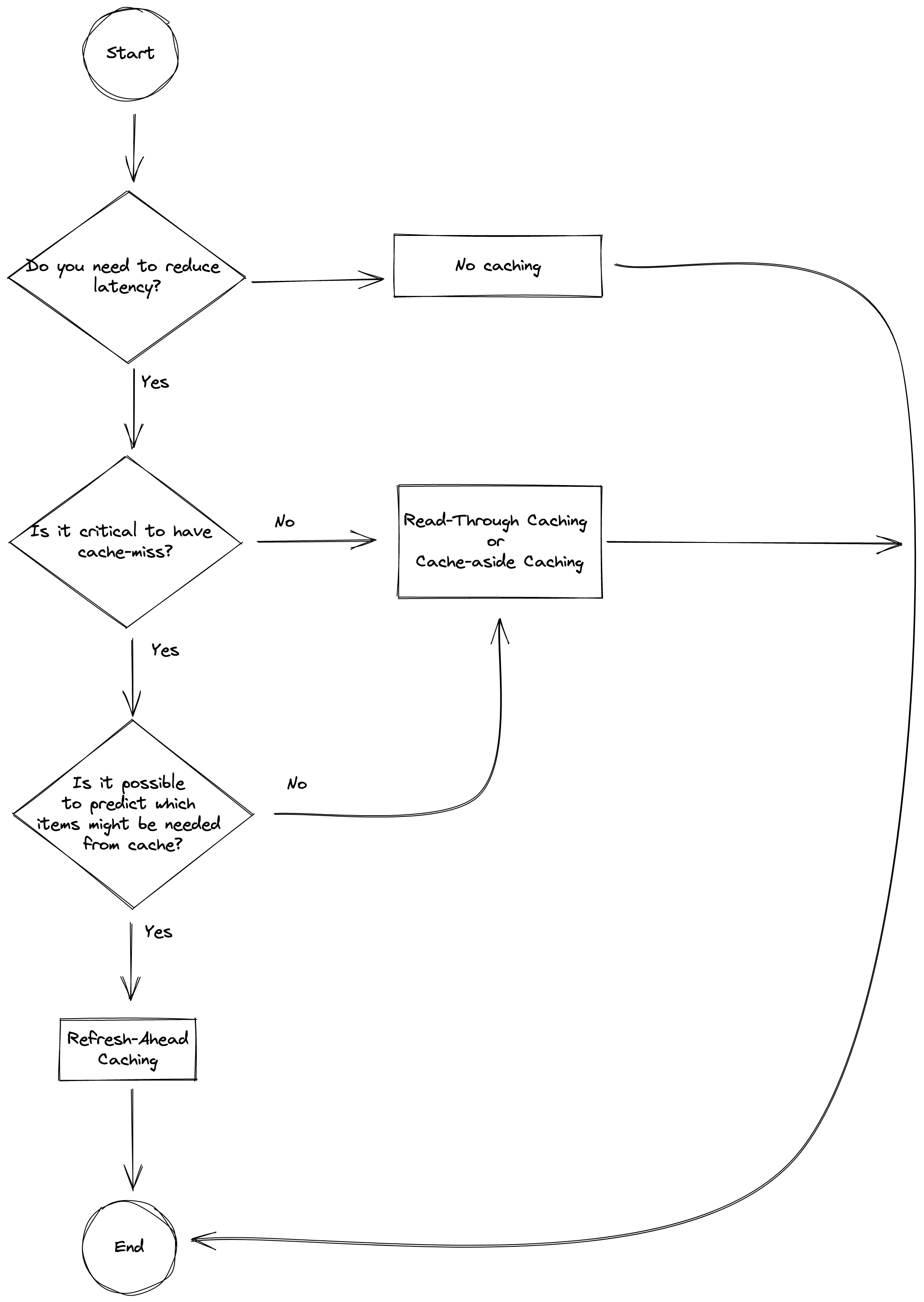
Deciding on which one to choose.
This is a very simplistic decision-making diagram that might help you start thinking about your use-cases and scenarios. This should not be treated as a main driving factor. The final decision should be made only after a proper design document review.